Con la crescente importanza della privacy dei dati, della sicurezza e dell'allocazione efficiente delle risorse, il rilevamento del tipo di file è una sfida critica ma spesso trascurata dalle organizzazioni. L'intelligenza artificiale (AI) sta rivoluzionando la verifica del tipo di file, un componente fondamentale della piattaformaMetaDefender , in quanto è in grado di rilevare i file contraffatti utilizzando l'apprendimento automatico. Ciò consente di aumentare l'accuratezza del rilevamento e di operare a livelli di efficienza molto più elevati rispetto alle tradizionali soluzioni di scansione statica.
Tecniche di spoofing del tipo di file
Se in passato cambiare l'estensione di un file (ad esempio, da .exe a .txt) era una tattica comune, le soluzioni di sicurezza sono diventate abili nel riconoscere questi trucchi di base. Questo ha portato gli aggressori a metodi più elaborati. Il moderno spoofing del tipo di file va oltre la semplice manipolazione dell'estensione. Gli aggressori possono manipolare la struttura interna di un file per imitare un tipo di file legittimo.
La vera sfida per gli aggressori non sta solo nel camuffare il file, ma anche nell'indurre l'utente a eseguirlo. Qui entrano spesso in gioco le tattiche di social engineering. Gli aggressori potrebbero camuffare il file con un'icona o un nome familiare, attirando l'utente ad aprirlo. In alternativa, potrebbero sfruttare le vulnerabilità del software che consentono l'esecuzione automatica indipendentemente dal tipo di file percepito.
In alcuni casi, i file contraffatti possono persino far parte di attacchi elaborati e in più fasi. Un file apparentemente innocuo potrebbe scaricare o installare il vero payload dannoso sul sistema di destinazione.
Lo spoofing del tipo di file rappresenta un rischio significativo perché aggira i tradizionali metodi di rilevamento basati sulle firme, che si basano su modelli predefiniti di codice dannoso. Questa tecnica ingannevole può essere utilizzata per distribuire varie minacce, tra cui ransomware, trojan e worm.
Perché il rilevamento accurato del tipo di file è importante
Considerate il filtraggio dei file, una pietra miliare della sicurezza organizzativa. Identificando accuratamente i tipi di file, le organizzazioni possono bloccare efficacemente i file dannosi. Questo protegge dalle minacce in entrata, come il malware, e migliora la privacy impedendo il flusso di informazioni sensibili in uscita. Inoltre, il filtraggio dei file non essenziali, come quelli di intrattenimento, ottimizza l'utilizzo delle risorse. Questo aspetto è particolarmente importante nel settore sanitario, dove le normative HIPAA impongono una forte protezione dei dati dei pazienti per salvaguardare i dati sanitari digitali dagli attacchi informatici. Il rilevamento affidabile dei tipi di file costituisce la spina dorsale della conformità del filtraggio dei file.
L'importanza del rilevamento del tipo di file va oltre il filtraggio dei file. Gli scanner antivirus la sfruttano spesso per dare priorità alle scansioni. Identificando in modo efficiente i tipi di file storicamente non associati ai virus, gli scanner possono concentrare le loro risorse sui file ad alto rischio, accelerando il rilevamento delle minacce dannose.
Il rilevamento accurato del tipo di file svolge un ruolo vitale, dietro le quinte, in varie pratiche di sicurezza e gestione dei dati, tra cui:

Il software di sicurezza tradizionale si basa sul rilevamento basato sulle firme, che identifica le minacce in base a modelli noti. Tuttavia, questo approccio è inefficace contro le minacce zero-day, che sono attacchi nuovi e sconosciuti al software di sicurezza. Il rilevamento accurato del tipo di file offre un vantaggio cruciale in questi scenari. Analizzando la struttura interna di un file, è in grado di identificare i file sospetti in base alle caratteristiche che si discostano dagli schemi previsti per un particolare tipo di file. Ciò consente di segnalare i file potenzialmente dannosi, anche se non sono mai stati incontrati prima.

Il rilevamento accurato del tipo di file consente ai sistemi di sicurezza di dare priorità alle minacce in modo più efficace. Invece di sprecare risorse per analizzare ogni singolo file, i sistemi possono concentrare i loro sforzi su quelli identificati come potenzialmente rischiosi in base al loro tipo di file. Ciò consente un approccio più snello alla sicurezza, in cui i file legittimi vengono elaborati rapidamente e le risorse vengono indirizzate verso l'analisi dei file sospetti per ulteriori indagini. In ultima analisi, ciò migliora la sicurezza generale di un'organizzazione, garantendo che le minacce vengano identificate e affrontate tempestivamente.

Conoscere la vera natura di un file permette ai sistemi di gestirlo correttamente. Tipi di file diversi richiedono metodi di elaborazione, tecniche di parsing e allocazioni di memoria differenti. Il rilevamento accurato del tipo di file garantisce che i file siano gestiti in modo appropriato, evitando malfunzionamenti e vulnerabilità che potrebbero derivare da file non correttamente identificati. Ad esempio, il tentativo di eseguire uno script dannoso mascherato da un innocuo file di immagine potrebbe portare a una violazione della sicurezza. Il rilevamento accurato del tipo di file aiuta a prevenire tali scenari, identificando la vera natura del file e impedendo l'esecuzione impropria.

Molte normative, come HIPAA e PCI DSS, impongono controlli specifici per la sicurezza dei dati. Il rilevamento accurato del tipo di file è un elemento cruciale per la conformità a queste normative. Aiuta le organizzazioni a identificare e classificare i dati sensibili, a implementare misure di sicurezza appropriate per i diversi tipi di file e a garantire l'archiviazione e la trasmissione sicura dei dati. In questo modo si riduce il rischio di violazione dei dati e di non conformità alle normative.
Tre metodi principali di verifica dei file
| Metodo | Pro | Contro |
| Estensione del file | Facile e veloce: controlla l'estensione del file per una rapida identificazione. Applicabile universalmente alla maggior parte dei sistemi operativi. | Facilmente ingannabile: Gli aggressori possono semplicemente rinominare i file dannosi con estensioni innocue. Limitato per le estensioni non standard e inaffidabile per Linux/Unix, dove le estensioni sono facoltative. |
| Byte magici | Più affidabile: Si basa su modelli di byte specifici (byte magici) per l'identificazione, offrendo una maggiore precisione rispetto alle estensioni. Può identificare file binari privi di estensioni. | Copertura limitata: Funziona solo per i tipi di file con byte magici definiti. Non tutti i tipi di file li hanno. Vulnerabile agli aggressori che alterano i byte magici per lo spoofing. Informazioni incoerenti provenienti da fonti diverse possono causare confusione. |
| Analisi della distribuzione dei caratteri | Scopre l'inganno: Analizza il contenuto effettivo per rivelare il vero tipo di file, potenzialmente esponendo malware nascosti e mascherati da un'estensione innocua. Fornisce informazioni preziose sul tipo di file di testo (ad esempio, testo normale o codice). | Costoso dal punto di vista computazionale: richiede la lettura e l'analisi del contenuto del file, rendendolo più lento di altri metodi. Sono possibili falsi allarmi in caso di contenuto unico o irregolare del file. Efficacia limitata per i file binari privi di una distribuzione distinta dei caratteri. |
Come OPSWAT sfrutta l'intelligenza artificiale per rilevare con precisione i tipi di file
Per una maggiore accuratezza e sicurezza, la tecnologia di OPSWAT File Type Verification va oltre questi metodi tradizionali sfruttando il flusso di lavoro di . MetaDefender Coreche li combina in un processo di filtraggio unico, potente ed efficiente. Riduce i tempi di elaborazione, ottenendo al contempo la massima accuratezza possibile.
Recentemente abbiamo anche aggiunto il rilevamento dell'apprendimento automatico per affrontare la sfida dei file di testo. Questi file, come i file di log, i file di script e i file readme, sono tutti semplicemente "testo" e non hanno caratteristiche distinte rivelate da altri metodi. L'analisi del contenuto è fondamentale per una classificazione accurata. L'errata classificazione di un file di testo può essere pericolosa, in quanto un file di script dannoso potrebbe essere eseguito senza essere individuato.
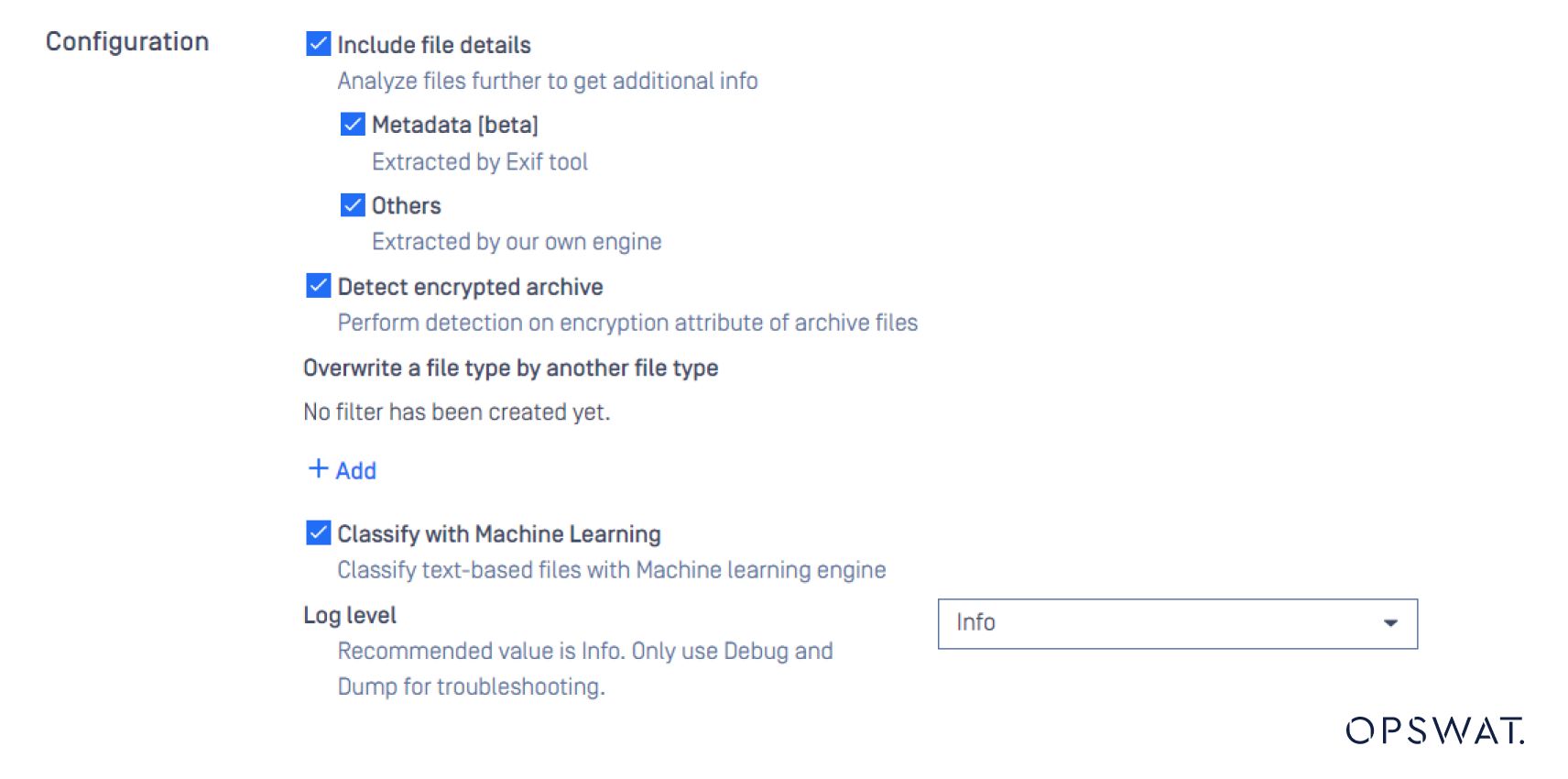
Configurazione della verifica del tipo di file basata sul testo in MetaDefender Core .
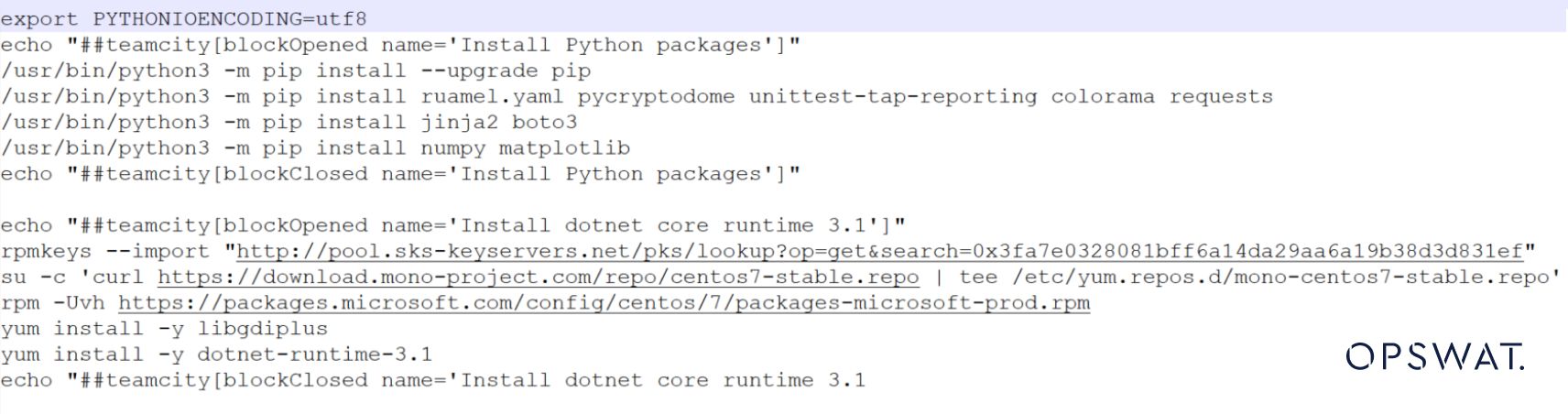
Vediamo questo esempio per capire come funziona.
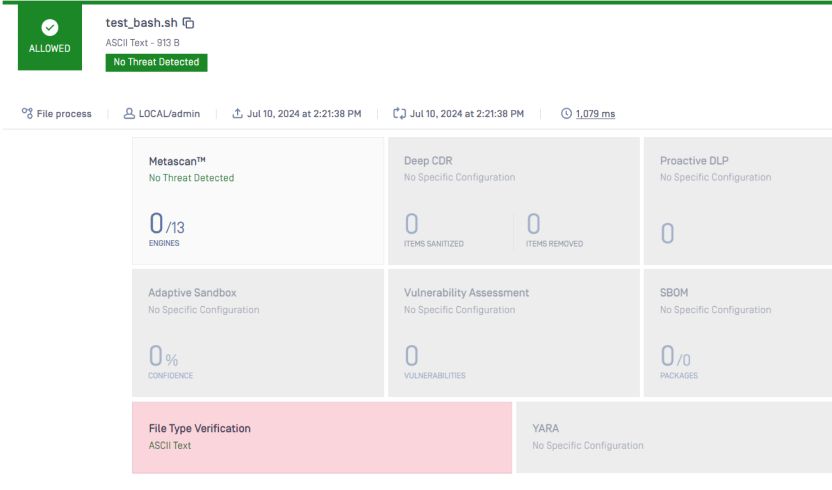
Vedere il confronto con e senza AI nel rilevamento dei tipi di file.
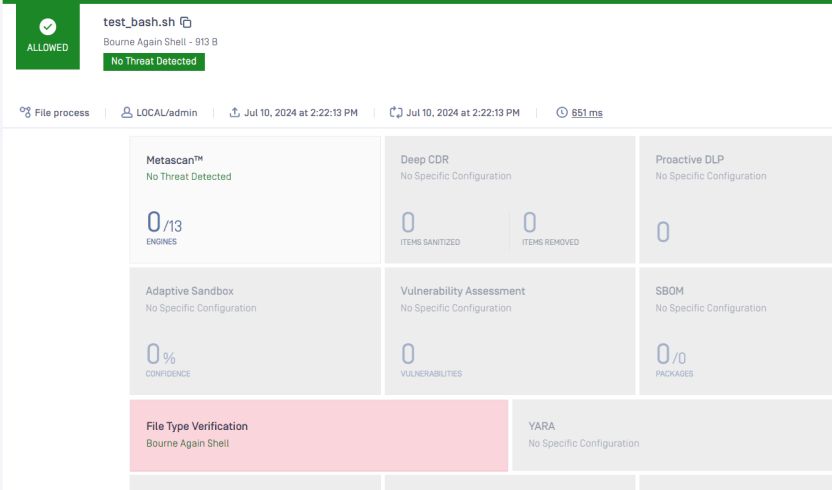
È interessante notare che si può modificare il file di shell per avere una breve descrizione in alto, come mostrato nell'esempio seguente.
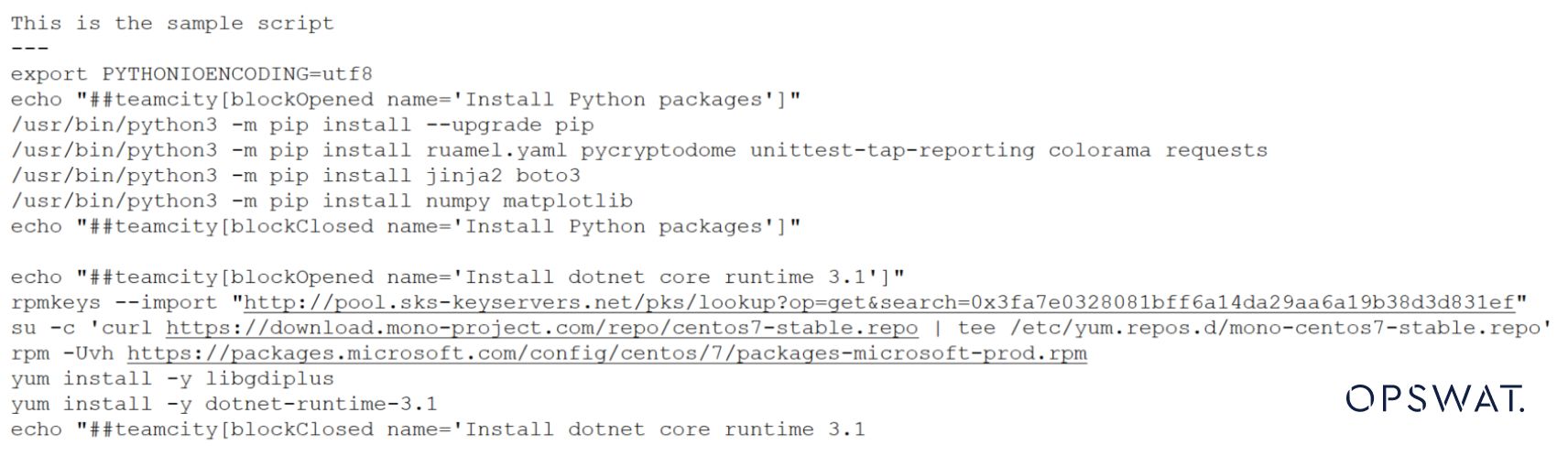
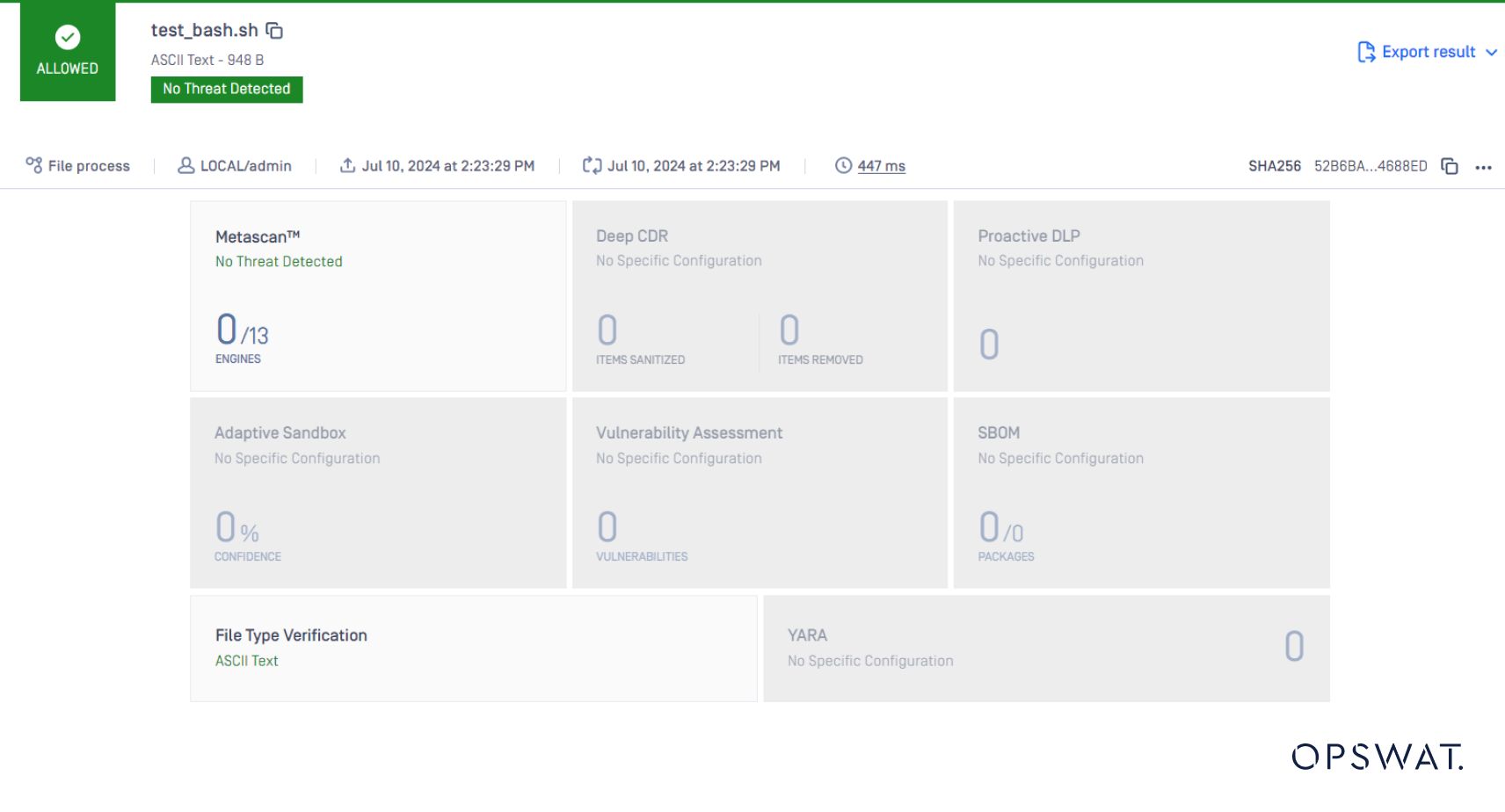
Il tipo di file lo rileverà nuovamente come testo, il che è vero. Non è più uno script.
Se commentiamo queste due righe, ma le manteniamo comunque come mostrato nell'immagine seguente.
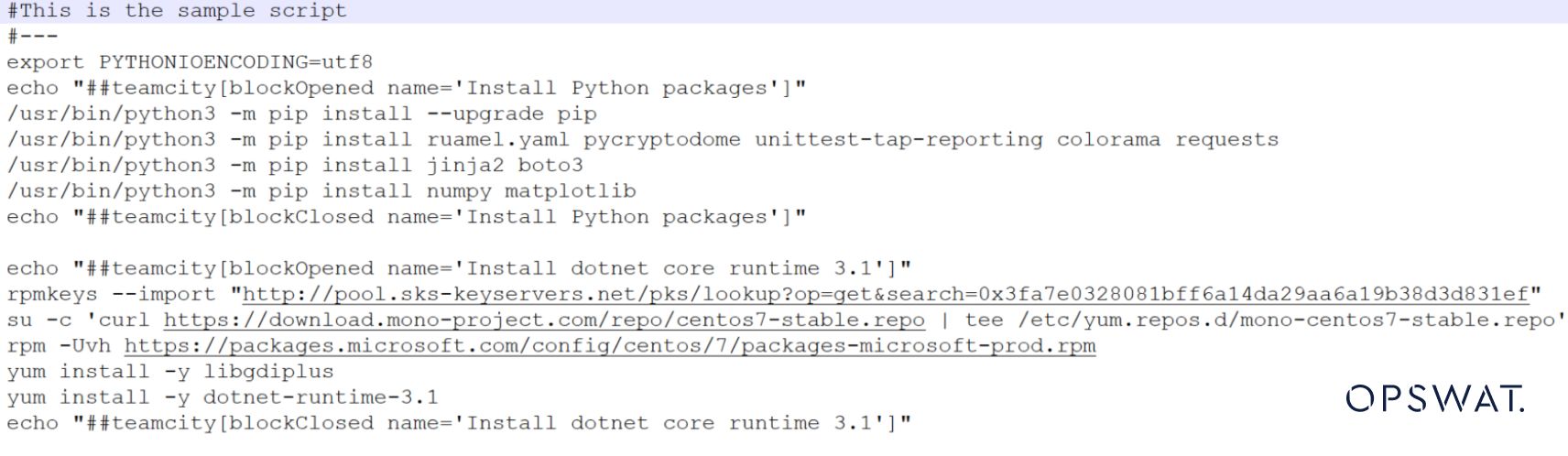
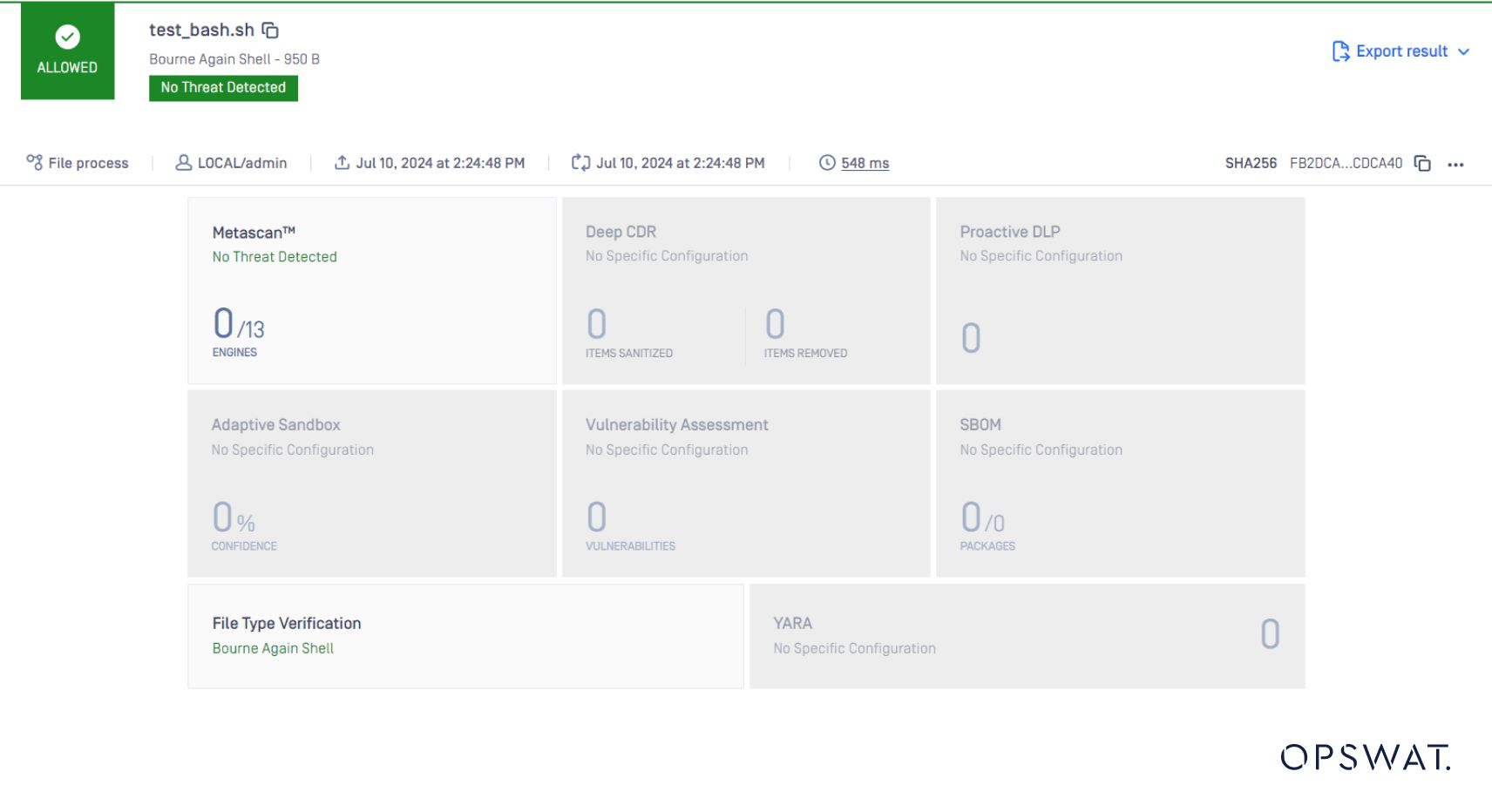
Il tipo di file deve essere:
Sfruttando l'apprendimento profondo per l'analisi dei file basati sul testo, OPSWAT File Type Verification raggiunge i seguenti obiettivi:
- Maggiore precisione: i modelli di intelligenza artificiale sono in grado di identificare anche i più sofisticati tentativi di spoofing del tipo di file, in particolare quelli basati su testo.
- Sicurezza a prova di futuro - La capacità di adattarsi alle nuove minacce garantisce una protezione continua.
- Maggiore efficienza - Il rilevamento accurato riduce la necessità di analisi manuali, risparmiando tempo e risorse.
Pensieri conclusivi
Mentre il rilevamento accurato dei tipi di file costituisce una prima linea di difesa fondamentale, OPSWAT File Type Verification con il miglioramento dell'intelligenza artificiale consente alle aziende di rafforzare ulteriormente la propria posizione di sicurezza. Sfruttando questa soluzione avanzata insieme ad altre misure di sicurezza come la prevenzione del malware veicolato dai file e la protezione dei dati sensibili, le aziende possono ottenere una difesa a più livelli che salvaguarda le loro organizzazioni dalle minacce di spoofing dei tipi di file e dalle violazioni dei dati.
Per ulteriori informazioni, rivolgetevi ai nostri esperti di cybersecurity.

