Il file spoofing rimane una delle tecniche più efficaci utilizzate dagli aggressori per aggirare i controlli di sicurezza tradizionali. L'anno scorso OPSWAT ha introdotto un motore di rilevamento dei tipi di file potenziato dall'intelligenza artificiale per colmare le lacune lasciate dagli strumenti tradizionali. Quest'anno, con il File Type Detection Model v3, abbiamo migliorato questa capacità concentrandoci sui tipi di file in cui l'accuratezza è più importante e in cui i sistemi tradizionali basati sulla logica falliscono sistematicamente.
OPSWAT File Type Detection Model v3 è stato progettato per affrontare la sfida specifica della classificazione affidabile di file ambigui e non strutturati, in particolare formati basati su testo come script, file di configurazione e codice sorgente. A differenza dei classificatori generici, questo modello è stato creato appositamente per i casi d'uso della cybersecurity, in cui l'errata classificazione di uno script di shell o il mancato rilevamento di un documento contenente macro incorporate, come un file Word con codice VBA, può introdurre un rischio significativo per la sicurezza.
Perché il vero rilevamento del tipo di file è fondamentale
La maggior parte dei sistemi di rilevamento si basa su tre approcci comuni:
- Estensione del file: Questo metodo controlla il nome del file per determinarne il tipo in base all'estensione, ad esempio .doc o .exe. È veloce e ampiamente compatibile con tutte le piattaforme. Tuttavia, è facilmente manipolabile. Un file dannoso può essere rinominato con un'estensione dall'aspetto sicuro e alcuni sistemi ignorano completamente le estensioni, rendendo questo approccio inaffidabile.
- Magic Bytes: Si tratta di sequenze fisse che si trovano all'inizio di molti file strutturati, come PDF o immagini. Questo metodo migliora l'accuratezza rispetto alle estensioni dei file esaminando il loro contenuto effettivo. Lo svantaggio è che non tutti i tipi di file hanno schemi di byte ben definiti. I byte magici possono anche essere falsificati e gli standard incoerenti tra gli strumenti possono generare confusione.
- Analisi della distribuzione dei caratteri: Questo metodo analizza il contenuto effettivo di un file per dedurne il tipo. È particolarmente utile per identificare formati basati su testo poco strutturati, come script o file di configurazione. Sebbene fornisca una visione più approfondita, comporta costi di elaborazione più elevati e può produrre falsi positivi con contenuti insoliti. Inoltre, è meno efficace per i file binari che non presentano modelli di caratteri leggibili.
Questi metodi funzionano bene per i formati strutturati, ma diventano inaffidabili se applicati a file non strutturati o basati su testo. Ad esempio, uno script di shell con comandi minimi può assomigliare molto a un file di testo. Molti di questi file non hanno intestazioni forti o marcatori coerenti, rendendo insufficiente la classificazione basata su modelli di byte o estensioni. Gli aggressori sfruttano questa ambiguità per camuffare gli script dannosi da documenti o log innocui.
Gli strumenti tradizionali come TrID e LibMagic non sono stati progettati per questo livello di sfumature. Pur essendo efficaci per la categorizzazione generale dei file, erano ottimizzati per l'ampiezza e la velocità, non per il rilevamento specializzato in base a vincoli di sicurezza.
Come funziona il modello di rilevamento del tipo di file v3
Il processo di formazione del File Type Detection Model v3 consiste in due fasi. Nella prima fase, viene eseguito un pre-training adattato al dominio utilizzando il Masked Language Modeling (MLM), che consente al modello di apprendere la sintassi e i modelli strutturali specifici del dominio. Nella seconda fase, il modello viene messo a punto su un set di dati supervisionato in cui ogni file è annotato esplicitamente con il suo vero tipo di file.
Il set di dati è una miscela curata di file regolari e campioni di minacce, che garantisce un forte equilibrio tra accuratezza del mondo reale e rilevanza per la sicurezza. OPSWAT mantiene il controllo sui dati di addestramento, consentendo un continuo perfezionamento dei formati più importanti per le operazioni di sicurezza.
La componente AI viene applicata con precisione, non in maniera generalizzata. Il File Type Detection Model v3 si concentra su tipi di file ambigui e non strutturati che i metodi di rilevamento tradizionali non sono in grado di gestire in modo efficace, come script, log e testo formattato in modo non chiaro in cui la struttura è incoerente o assente. Il tempo medio di inferenza rimane inferiore a 50 millisecondi, rendendolo efficiente per i flussi di lavoro in tempo reale attraverso il caricamento sicuro dei file, l'applicazione degli endpoint e le pipeline di automazione.
Risultati del benchmark
Il motore di rilevamento dei tipi di file di OPSWAT è stato confrontato con i principali strumenti di rilevamento dei tipi di file utilizzando un set di dati ampio e diversificato. Il confronto ha incluso punteggi F1 su 248.000 file e circa 100 tipi di file.
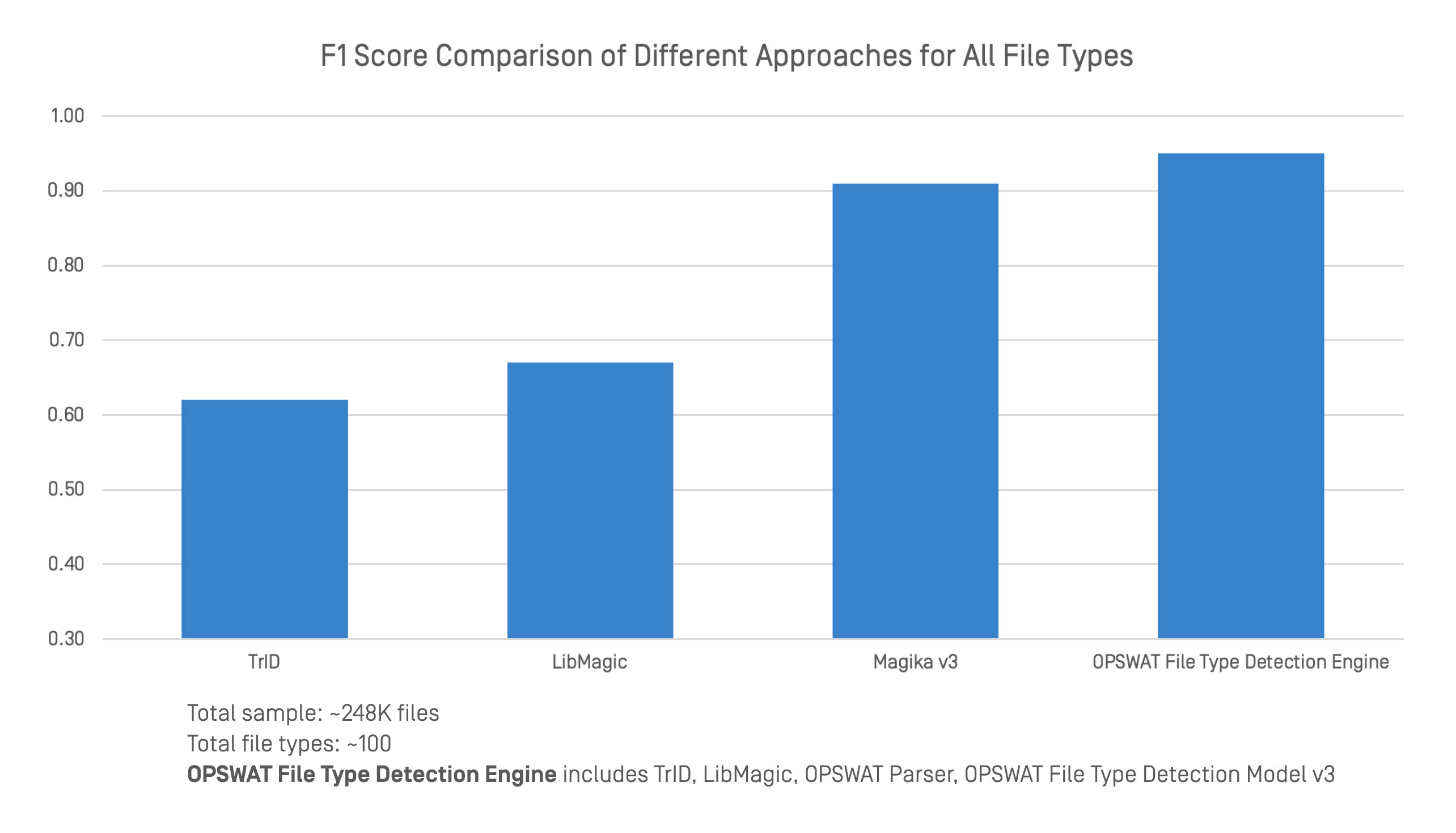
Il motore di rilevamento dei tipi di file OPSWAT integra diverse tecniche, tra cui TrID, LibMagic e le tecnologie proprie di OPSWAT, come i parser avanzati e il File Type Detection Model v3. Questo approccio combinato offre una classificazione più forte e affidabile per i formati strutturati e non strutturati.
Nei test di benchmark, il motore ha ottenuto un'accuratezza complessiva superiore a quella di ogni singolo strumento. Mentre TrID, LibMagic e Magika v3 ottengono buoni risultati in alcune aree, la loro precisione diminuisce quando mancano le intestazioni dei file o il contenuto è ambiguo. Grazie alla stratificazione del rilevamento tradizionale con l'analisi approfondita del contenuto, OPSWAT mantiene prestazioni costanti anche quando la struttura è debole o intenzionalmente fuorviante.
File di testo e script
I formati basati su testo e script sono spesso coinvolti in minacce trasmesse da file e movimenti laterali. Abbiamo condotto un test mirato su 169.000 file in formati quali .sh, .py, .ps1, e .conf.
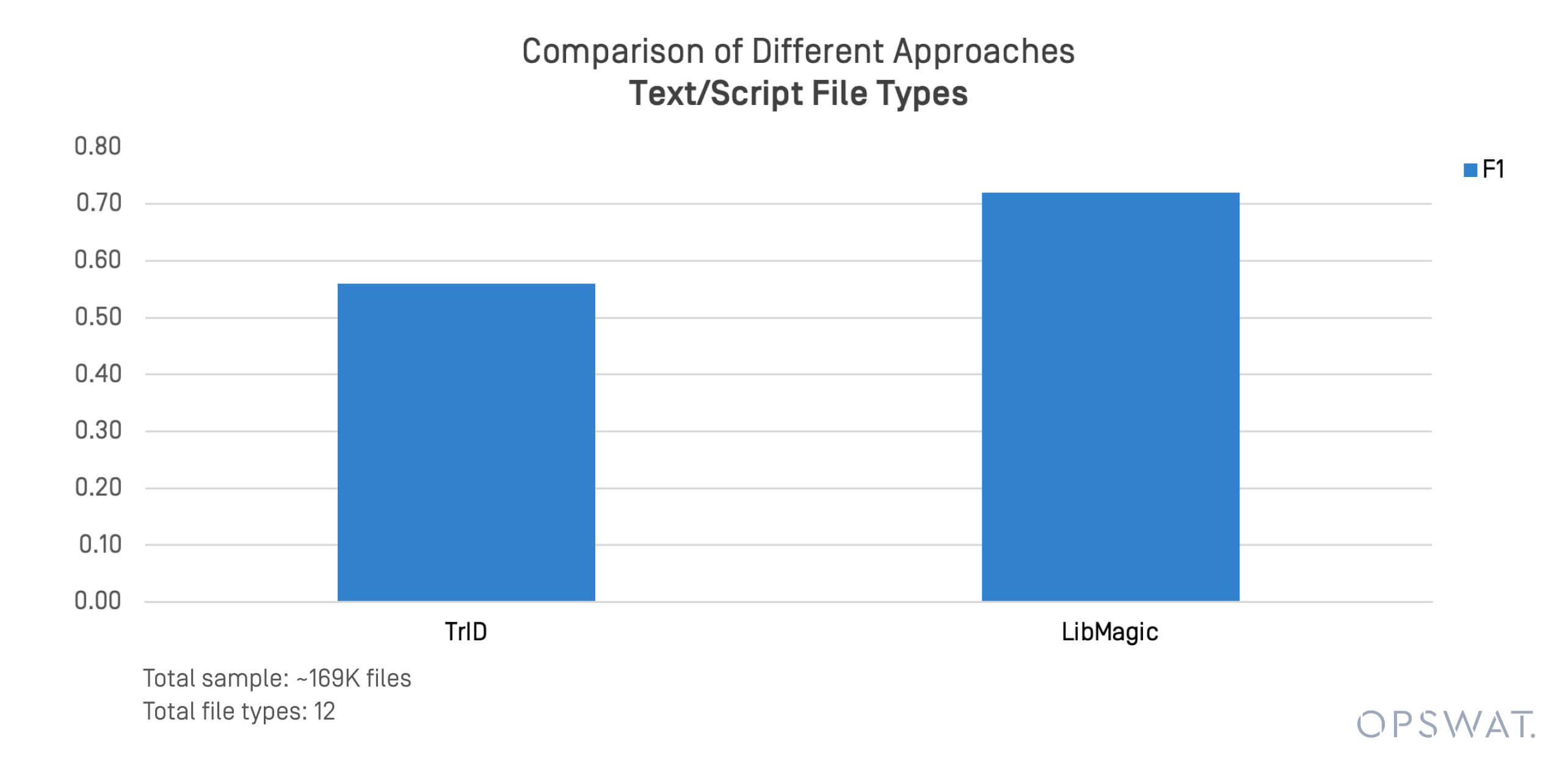
TrID e LibMagic hanno mostrato dei limiti nel rilevare questi file non strutturati. Le loro prestazioni si riducono rapidamente quando il contenuto del file si discosta dagli schemi di byte previsti.
Modello di rilevamento del tipo di file v3 vs Magika v3
Abbiamo valutato OPSWAT File Type Detection Model v3 rispetto a Magika v3, il classificatore AI open source di Google, su 30 tipi di file di testo e di script utilizzando lo stesso dataset di 500.000 file.
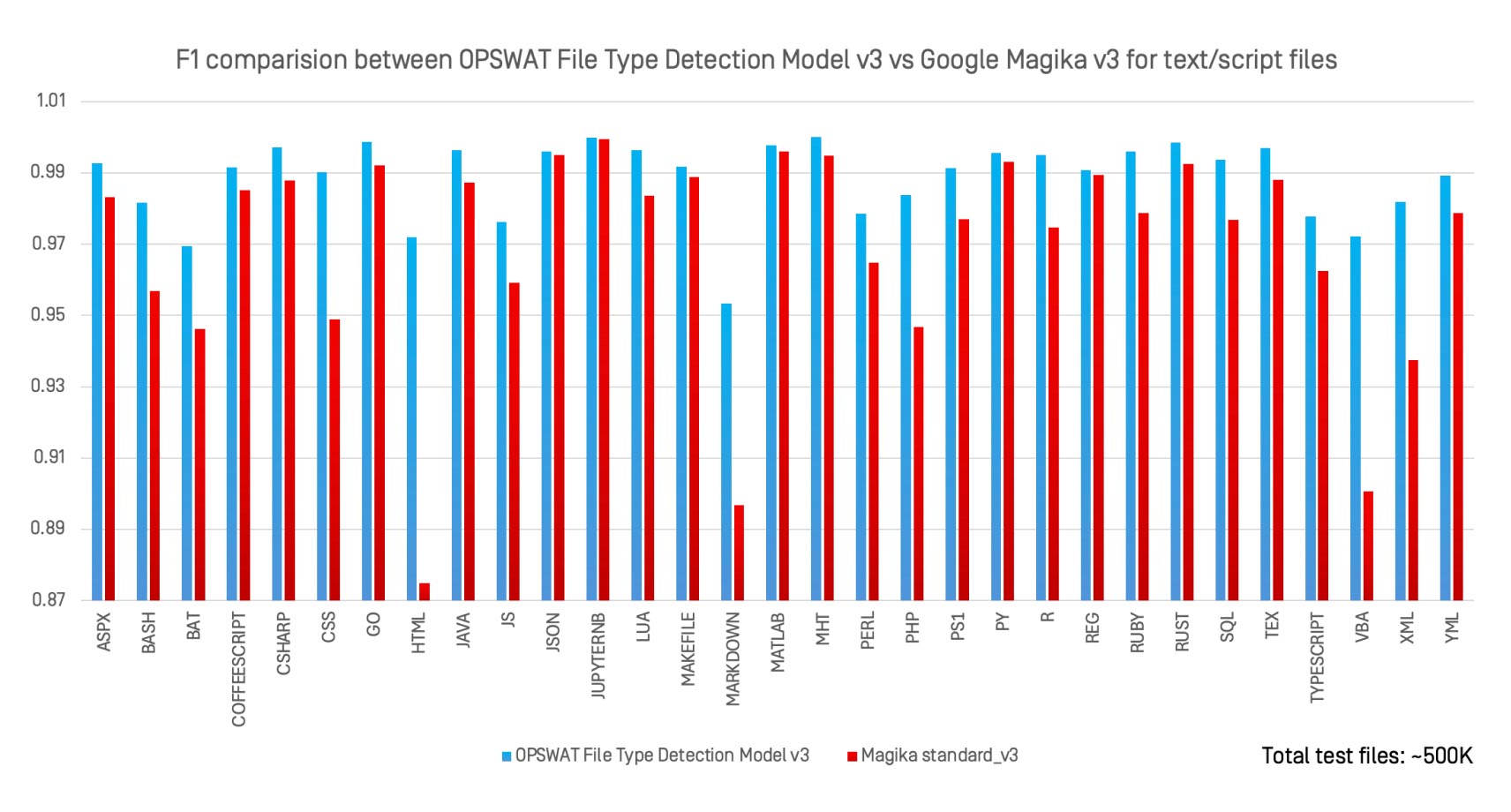
Osservazioni principali:
- File Type Detection Model v3 ha eguagliato o superato Magika in quasi tutti i formati.
- I guadagni più consistenti sono stati registrati nei formati definiti in modo non vincolante, come ad esempio
.bat, .perl, .html,e .xml. - A differenza di Magika, che è stato progettato per l'identificazione generica, File Type Detection Model v3 è ottimizzato per i formati ad alto rischio in cui l'errata classificazione ha gravi implicazioni per la sicurezza.
Casi d'uso principali
Caricamento, scaricamento e trasferimento di file Secure
Impedite ai file mascherati o dannosi di entrare nel vostro ambiente attraverso portali web, allegati di posta elettronica o sistemi di trasferimento di file. Il rilevamento potenziato dall'intelligenza artificiale va oltre le estensioni e le intestazioni MIME per identificare script, macro o eseguibili incorporati nei file rinominati.
Pipeline DevSecOps
Bloccate gli artefatti non sicuri prima che contaminino gli ambienti di creazione o distribuzione del software. Convalidando il vero tipo di file in base al contenuto effettivo, MetaDefender Core assicura che solo i formati approvati passino attraverso le pipeline CI/CD, riducendo il rischio di attacchi alla supply chain e mantenendo la conformità con le pratiche di sviluppo sicuro.
Applicazione della conformità
Il rilevamento accurato dei tipi di file è essenziale per soddisfare i mandati normativi come HIPAA, PCI DSS, GDPR e NIST 800-53, che richiedono un controllo rigoroso dell'integrità dei dati e della sicurezza del sistema. Rilevare e bloccare i tipi di file spoofed o non autorizzati aiuta a far rispettare le politiche che impediscono l'esposizione dei dati sensibili, a mantenere la prontezza delle verifiche e a evitare costose sanzioni.
Pensieri finali
I classificatori di file generici come Magika sono utili per la categorizzazione di contenuti di ampio respiro. Ma nella cybersecurity la precisione conta più della copertura. Un singolo script o macro mal classificato può fare la differenza tra il contenimento e la compromissione.
Il motore di rilevamento dei tipi di file OPSWAT offre questa precisione. Combinando l'analisi dei tipi di file potenziata dall'intelligenza artificiale con metodi di rilevamento collaudati, fornisce un livello affidabile di classificazione laddove gli strumenti tradizionali falliscono, soprattutto in caso di formati ambigui o non strutturati. Non si tratta di sostituire tutto, ma di rafforzare i punti deboli critici del vostro stack di sicurezza con un rilevamento in tempo reale e consapevole del contesto.

