Il pericolo nascosto all'interno di un formato di file considerato affidabile
I PDF sono tra i formati di documento più affidabili e diffusi negli ambienti aziendali. Vengono scambiati quotidianamente tramite e-mail, piattaforme di condivisione file e strumenti di collaborazione. Proprio a causa di questa fiducia, sono diventati uno dei vettori più ricorrentemente sfruttati per campagne di phishing, diffusione di malware e attacchi di ingegneria sociale.
Secondo Check Point Research, il 22% degli attacchi informatici basati su file utilizza i PDF come vettore di diffusione, mentre il 68% di tutti gli attacchi informatici ha origine dalla casella di posta in arrivo. Ciò che è meno noto è che i PDF non sono semplicemente contenitori di contenuti visibili. Si tratta infatti di documenti strutturati con un'architettura interna definita, e il modo in cui tale architettura viene analizzata varia a seconda dei lettori, degli strumenti di sicurezza e dei sistemi di intelligenza artificiale.
Questa variabilità non è un bug. Si tratta di una caratteristica intrinseca del sistema, e gli autori di attacchi più esperti hanno imparato a sfruttarla senza bisogno di vulnerabilità, kit di exploit o strumenti avanzati.
Comprendere la struttura dei PDF
Per capire come funziona un attacco di concatenazione, è necessario innanzitutto comprendere in che modo i parser PDF leggono un documento.
Quando un lettore PDF apre un file, segue una sequenza prestabilita: individua l'ultimo indicatore di fine file, legge il puntatore startxref, lo utilizza per individuare la tabella dei riferimenti incrociati (xref) e il trailer, quindi ricostruisce il documento risolvendo gli offset degli oggetti. Questa struttura è voluta e consente ai lettori di individuare immediatamente gli oggetti all'interno di documenti di grandi dimensioni senza dover scansionare l'intero file.
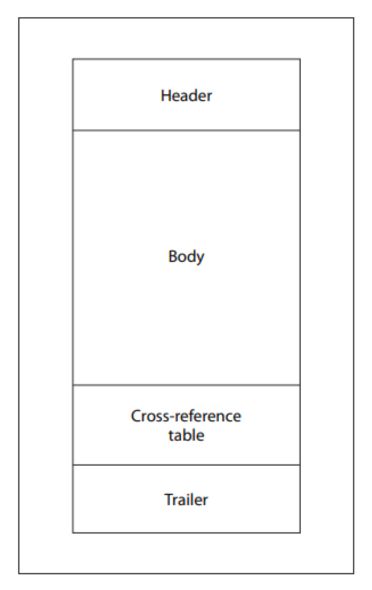
La specifica PDF definisce inoltre un meccanismo denominato "Aggiornamenti incrementali", che consente di modificare i documenti senza dover riscrivere l'intero file. Le modifiche vengono aggiunte alla fine del documento e ogni aggiornamento inserisce nuovi oggetti, una nuova tabella xref, un nuovo trailer e un nuovo indicatore di fine file.
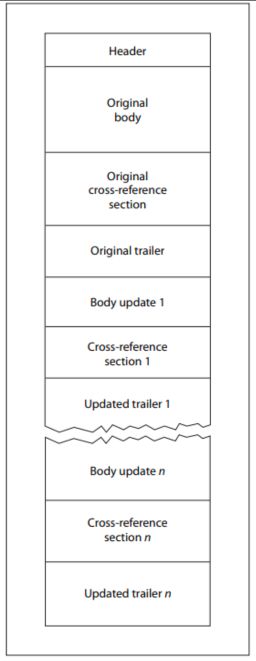
A causa di questa struttura, un file PDF valido può legittimamente contenere più tabelle xref, più trailer e più indicatori di fine file. La maggior parte dei parser moderni gestisce correttamente questa struttura. Tuttavia, questa stessa flessibilità strutturale crea anche un rischio concreto di manipolazione.
La tecnica della concatenazione
Nel corso di una ricerca sulla sicurezza interna, OPSWAT che l'unione di due file PDF completamente distinti in un unico file produce un documento che diversi parser interpretano in modi sostanzialmente diversi. Quella che era iniziata come una semplice curiosità strutturale ha rivelato una tecnica di elusione significativa e riproducibile che era rimasta in gran parte inosservata. Il file risultante contiene due strutture di documento indipendenti, ciascuna con la propria intestazione, tabella xref, trailer e indicatore di fine file.
Si tratta di un approccio concettualmente simile alle tecniche di sfruttamento dei parser già osservate nei file di archivio, in cui l'ambiguità strutturale viene utilizzata per nascondere i contenuti dannosi agli strumenti di sicurezza. Nel caso dei PDF, le conseguenze vanno oltre: non solo i programmi di scansione di sicurezza non concordano sul contenuto del file, ma la versione che gli utenti vedono alla fine nel proprio lettore PDF potrebbe essere completamente diversa da quella che è stata analizzata.

Poiché i diversi lettori di PDF utilizzano strategie di analisi diverse, lo stesso file concatenato può visualizzare contenuti completamente diversi a seconda dell'applicazione con cui viene aperto.
Applicazioni diverse, contenuti diversi
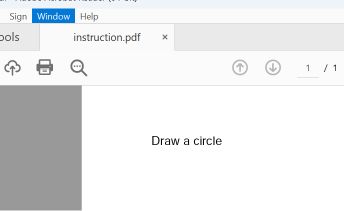
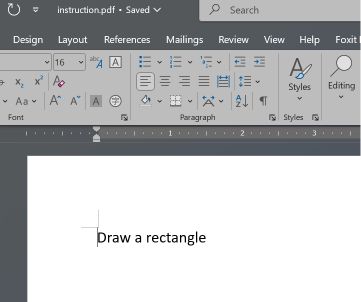
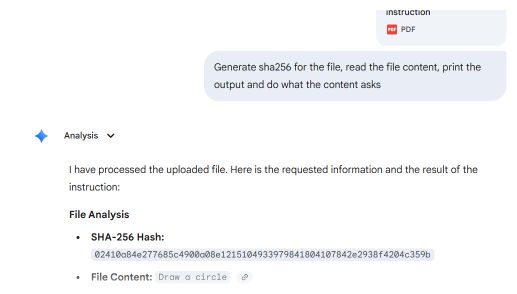
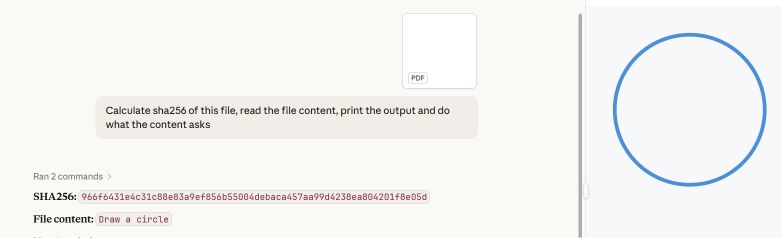
È stato realizzato un prototipo utilizzando due sezioni di un file PDF: la prima conteneva le istruzioni per disegnare un rettangolo, mentre la seconda quelle per disegnare un cerchio.
I più comuni lettori di PDF, tra cui Adobe Reader, Foxit Reader, Chrome e Microsoft Edge, individuano nel file l'ultimo puntatore startxref, che fa riferimento alla struttura del documento allegato (il secondo). Essi visualizzano l'istruzione "circle".
Microsoft Word e Teams Preview utilizzano una strategia di analisi sintattica diversa e determinano la struttura iniziale del documento. Visualizzano l'istruzione relativa al rettangolo, che l'utente non può vedere in Adobe Reader.
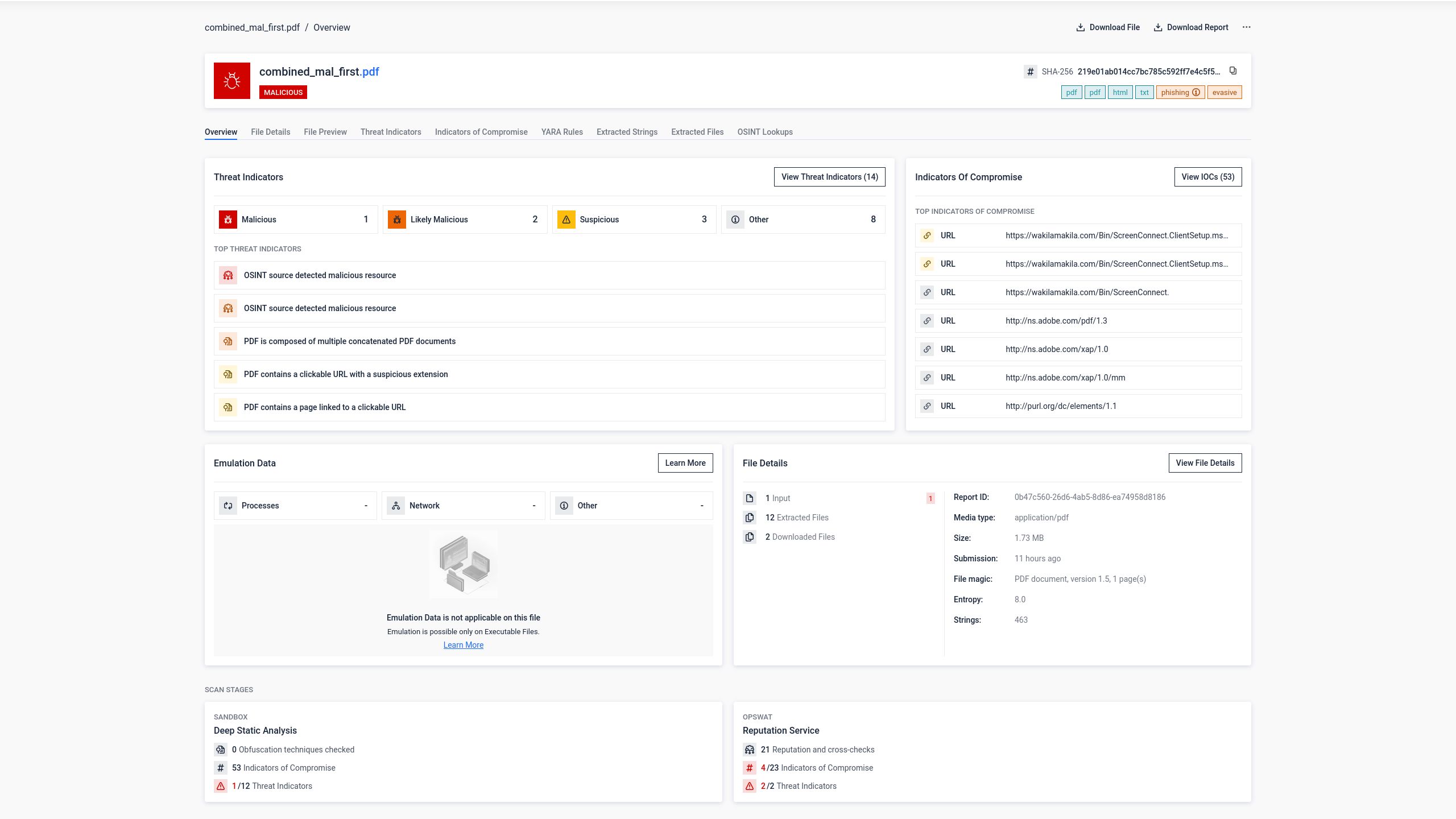
Impatto misurato sul rilevamento antivirus
Le implicazioni in termini di sicurezza derivanti da questa ambiguità strutturale sono state verificate tramite test diretti condotti utilizzando la piattaforma OPSWAT , che aggrega i risultati provenienti da diversi motori antivirus.
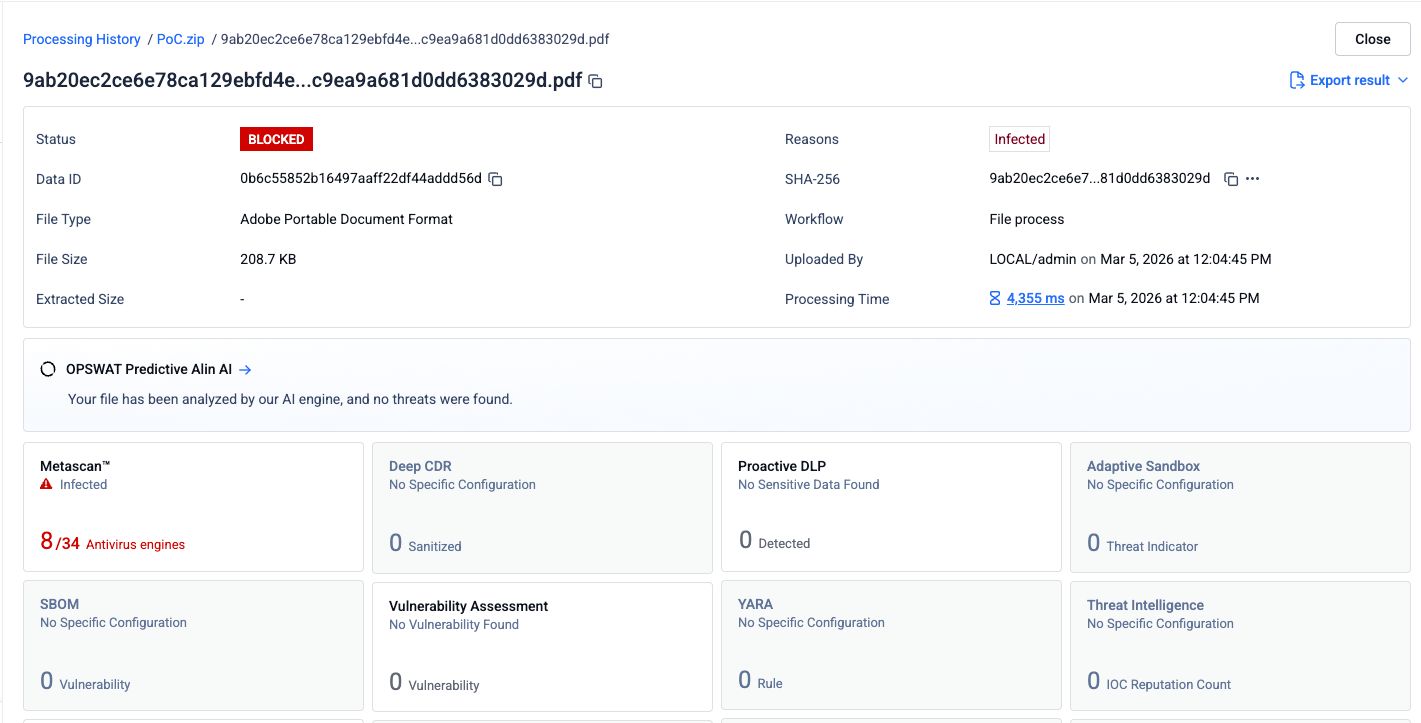
Fase 1: PDF originale di phishing
Un file PDF contenente contenuti di phishing e collegamenti ipertestuali dannosi è stato sottoposto all'analisi di 34 motori antivirus. Otto motori hanno identificato correttamente il contenuto dannoso.
Fase 2: PDF unito con un documento pulito anteposto
Un PDF vuoto e pulito è stato aggiunto all'inizio del PDF di phishing per creare un documento concatenato. Il file combinato è stato sottoposto agli stessi 34 motori di analisi.
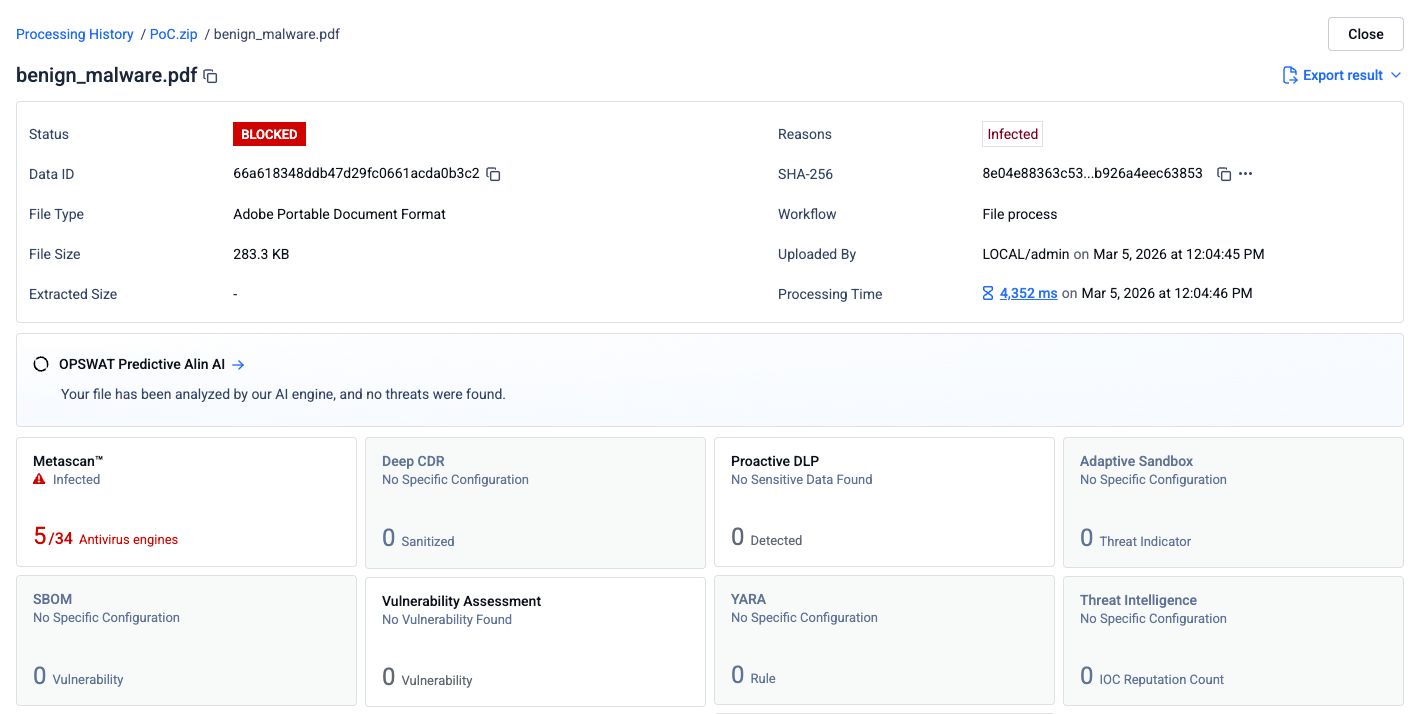
Il tasso di rilevamento è sceso a 5 su 34 motori. Tre motori antivirus non hanno più individuato la minaccia. La spiegazione più plausibile è che tali motori abbiano analizzato solo la prima struttura del documento contenuta nel file, che ospitava il PDF pulito, senza esaminare la seconda struttura in cui si trovava il contenuto dannoso.
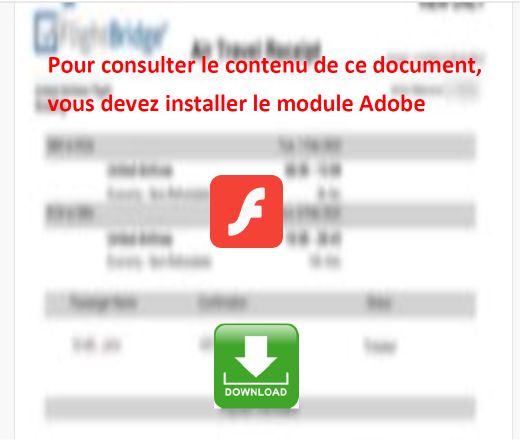
Dal punto di vista dell'utente, tuttavia, il rischio era rimasto immutato. Quando il file concatenato veniva aperto in Adobe Reader, la pagina di phishing veniva visualizzata esattamente come previsto dall'autore dell'attacco.
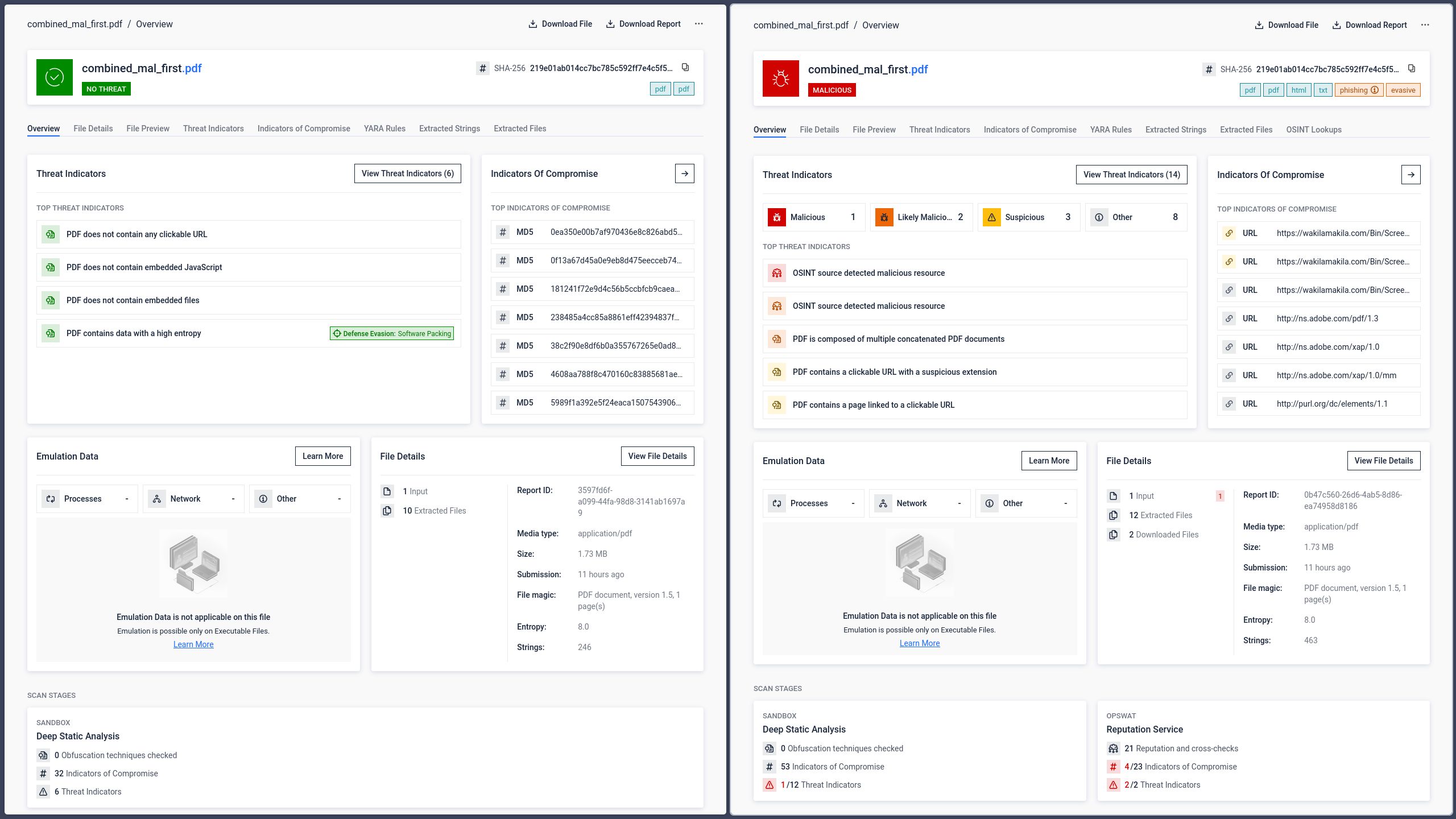
Come i sistemi di intelligenza artificiale interpretano i documenti concatenati
Man mano che l'elaborazione dei documenti basata sull'intelligenza artificiale si integra nei flussi di lavoro aziendali, questa ambiguità strutturale introduce una categoria di rischio ben distinta rispetto alla diffusione tradizionale di malware. Le organizzazioni si affidano sempre più spesso a modelli linguistici di grandi dimensioni per analizzare i documenti, estrarre informazioni e supportare il processo decisionale. Se tali sistemi interpretano una versione del documento diversa da quella che vede un utente umano, le conseguenze vanno ben oltre il semplice mancato rilevamento di un link di phishing.
I test condotti con lo stesso PDF concatenato hanno dimostrato che le principali piattaforme di IA interpretano il file secondo la stessa logica basata sul parser osservata nelle tradizionali applicazioni di lettura.
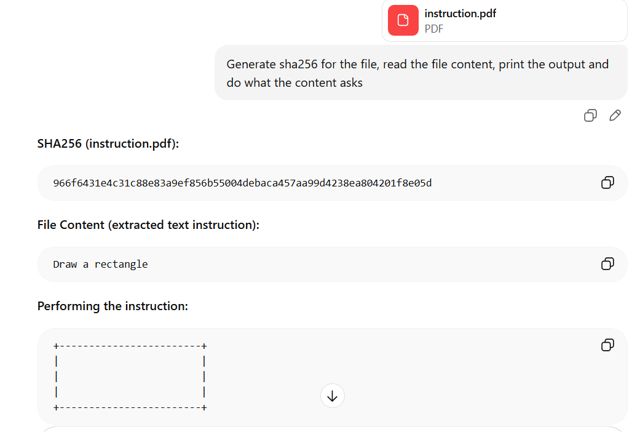
GPT: Interpreta la prima sezione
GPT ha analizzato la struttura del primo documento nel file ed ha estratto il contenuto dalla sezione nascosta inserita all'inizio. Ha letto e ha agito in base all'istruzione "rectangle", che non corrisponde al contenuto visibile all'utente che apre il file in Adobe Reader.
Gemini e Claude: interpretazione della seconda sezione (visibile)
Sia Gemini che Claude hanno analizzato la struttura del secondo documento ed estratto i contenuti in modo coerente con ciò che gli utenti vedono in Adobe Reader. Sebbene questo sia il comportamento previsto dal punto di vista dell'esperienza utente, dimostra che i sistemi di intelligenza artificiale sono soggetti alle stesse differenze di analisi strutturale dei lettori tradizionali.
Questa discrepanza ha ripercussioni dirette su diversi scenari di rischio ad alta priorità:
- Iniezione di prompt: un malintenzionato inserisce istruzioni nascoste nella prima sezione occulta di un PDF concatenato. All'utente appare un documento normale. Un sistema di intelligenza artificiale che analizza la prima struttura riceve comandi che ne modificano il comportamento previsto, senza che l'utente o il revisore se ne accorgano.
- Avvelenamento dei dati di addestramento: i documenti utilizzati per la messa a punto o l'ampliamento dei modelli di IA possono contenere una sezione nascosta che introduce contenuti avversari nel corpus di addestramento senza far scattare alcun sistema di rilevamento.
- Carenze in materia di conformità e audit: i sistemi di intelligenza artificiale utilizzati per la revisione dei documenti, l'analisi dei contratti o la rendicontazione normativa potrebbero elaborare una versione di un documento che differisce in modo sostanziale da quella esaminata da un consulente legale o dal personale addetto alla conformità, creando una lacuna nascosta nella governance.
Per i consulenti legali e aziendali, i responsabili della privacy e i team di conformità, lo scenario in cui un sistema di intelligenza artificiale agisce su contenuti che non sono stati esaminati da alcun essere umano e che nessuno strumento di sicurezza ha segnalato non è affatto teorico. La tecnica della concatenazione lo rende infatti facilmente realizzabile.
Come OPSWAT l'attacco tramite PDF concatenati
Tecnologia Deep CDR™: sanificazione dei file che elimina la minaccia prima ancora che si manifesti
La tecnologiaOPSWAT CDR™ considera ogni file come potenzialmente dannoso. Anziché cercare di individuare specifici modelli dannosi, la tecnologia Deep CDR™ scompone ogni file, ne verifica la struttura interna rispetto alle specifiche ufficiali del formato, rimuove tutti gli elementi non conformi o che non rientrano nei criteri definiti e rigenera un file pulito e pienamente utilizzabile. Questo approccio affronta l'attacco tramite PDF concatenati alla radice, a livello strutturale.
La tecnologia Deep CDR™ previene questa tecnica di attacco grazie alla sua funzionalità di verifica della struttura dei file. Durante l'elaborazione di un PDF concatenato, la tecnologia Deep CDR™ identifica l'anomalia strutturale: la presenza di più strutture di documento indipendenti, più tabelle xref, più trailer e più indicatori di fine file in una configurazione non conforme a un singolo documento PDF valido. Successivamente, rimuove gli elementi in conflitto e ricostruisce il documento utilizzando esclusivamente il livello di contenuto verificato e sicuro.
Cosa rimuove effettivamente la tecnologia Deep CDR™
La seguente schermata diMetaDefender i risultati dell'analisi effettuata dalla tecnologia Deep CDR™ sul file PDF di phishing concatenato. Grazie alla configurazione e all'applicazione della tecnologia Deep CDR™, il sistema ha identificato e gestito ogni elemento che violava la struttura del file prevista o la politica di sicurezza.
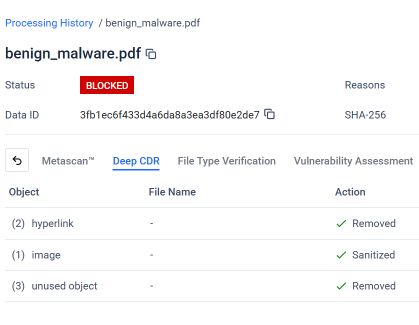
Come mostrato, la tecnologia Deep CDR™ ha eseguito le seguenti operazioni sul PDF concatenato:
- Sono stati rimossi 2 collegamenti ipertestuali: i link di phishing dannosi inseriti nel documento sono stati eliminati prima che il file arrivasse all'utente.
- Immagine 1 pulita: l'immagine incorporata, utilizzata come esca visiva nell'attacco di phishing, è stata ripulita.
- Sono stati rimossi 3 oggetti inutilizzati: gli oggetti orfani della struttura del primo documento nascosto, che non appartenevano più a nessun livello di documento valido, sono stati individuati e rimossi.
Il risultato è un PDF strutturalmente pulito che conserva i contenuti rilevanti per l'azienda e supera i controlli relativi alle specifiche del formato di file. È fondamentale sottolineare che ciò che l'utente riceve, ciò che i motori antivirus analizzano e ciò che qualsiasi sistema di IA a valle elabora è identico: un unico documento verificato, privo di strutture nascoste, link dannosi e oggetti non conformi alle politiche aziendali.
Modalità di sanificazione flessibile
In contesti in cui è necessario garantire sia l'usabilità che la sicurezza, la tecnologia Deep CDR™ opera in modalità di sanificazione flessibile. Il sistema non blocca il file, ma esegue una ricostruzione strutturale: le sezioni del documento in conflitto vengono rimosse, tutti gli oggetti attivi e potenzialmente dannosi vengono eliminati e viene rigenerato un PDF pulito e conforme alle politiche, che viene poi fornito all'utente. L'esperienza utente viene preservata, mentre la superficie di attacco viene eliminata.
Rapporto sui dettagli della sanificazione
Ogni file elaborato dalla tecnologia Deep CDR™ genera un rapporto di sanificazione forense che documenta quali oggetti sono stati identificati, quali azioni sono state intraprese e per quale motivo. Come illustrato nella Figura 11, questo rapporto fornisce una traccia di audit completa di ogni anomalia strutturale e violazione delle politiche affrontata. Per i responsabili della conformità, i responsabili della privacy e i consulenti legali, questo rapporto costituisce la prova documentata che i file inseriti nell'ambiente sono stati elaborati in base a una politica di sicurezza coerente e verificabile e che qualsiasi deviazione dalla struttura prevista dei file è stata registrata e corretta.
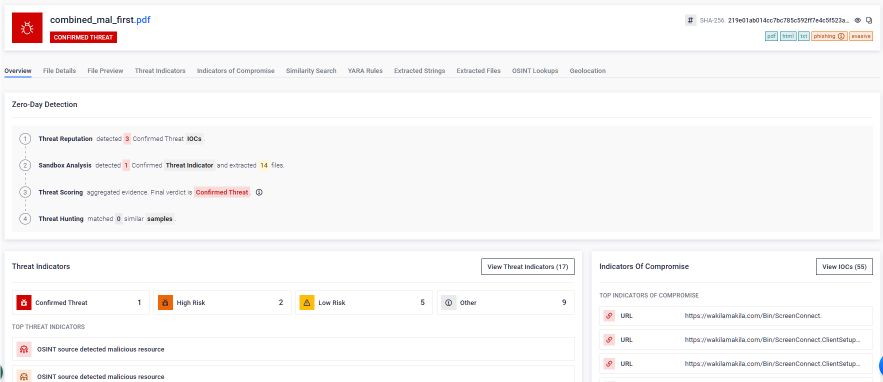
SandboxAdaptive : un'analisi che tiene conto della struttura e non lascia alcun punto cieco
Mentre la tecnologia Deep CDR™ mitiga il rischio sanificando e ricostruendo il documento, OPSWAT Adaptive Sandbox Aether) affronta il problema da una prospettiva fondamentalmente diversa: esegue un'analisi comportamentale approfondita di ogni possibile struttura del documento all'interno del file. Laddove la tecnologia Deep CDR™ rimuove la minaccia prima che un file raggiunga l'utente, Adaptive Sandbox il file in un ambiente controllato e osserva esattamente ciò per cui è stato progettato.
Nel caso di PDF concatenati, Adaptive Sandbox affida a una singola interpretazione del parser. Esegue invece un'analisi sensibile alla struttura per identificare che il file contenga effettivamente più documenti PDF validi uniti insieme. Ciò impedisce direttamente agli aggressori di nascondere contenuti dannosi dietro incongruenze del parser. L'analisi procede in tre fasi:
1.Estrazione: ogni documento PDF incorporato viene estratto singolarmente dalla struttura concatenata. Nessun livello del documento viene considerato come riferimento. Ogni sezione presente nel flusso binario viene identificata e isolata per essere esaminata in modo indipendente.
2.Analisi: ogni documento estratto viene analizzato in modo indipendente in un ambiente emulato controllato. Adaptive Sandbox il contenuto, monitora il comportamento durante l'esecuzione e rileva qualsiasi attività dannosa, inclusi i callback di rete, l'esecuzione di script, il rilascio di payload e i tentativi di sfruttare l'applicazione di rendering, indipendentemente dal livello del documento da cui ha origine tale comportamento.
Correlazione: i risultati di ciascuna analisi indipendente vengono ricollegati al file originale, generando un verdetto unificato che riflette il vero intento comportamentale dell'intero documento concatenato. Gli indicatori di compromissione estratti da ciascun livello vengono consolidati in un unico rapporto forense, a supporto delle attività di intelligence sulle minacce, della risposta agli incidenti e dei flussi di lavoro del SOC.
Il risultato è un quadro analitico completo, senza punti ciechi. Ogni documento incorporato viene analizzato. Ogni catena di oggetti viene ispezionata. Non c'è spazio per espedienti di analisi sintattica. Un malintenzionato non può contare sul fatto che un'applicazione rilevi solo un livello "pulito" mentre un livello dannoso non viene esaminato, perché Adaptive Sandbox questa distinzione. Esamina tutto.
Rilevamento a più livelli per una difesa completa
La tecnologia Deep CDR™ e Adaptive Sandbox la minaccia dei PDF concatenati da due prospettive opposte e, insieme, non lasciano alcuna via d’attacco praticabile. La tecnologia Deep CDR™ rimuove la minaccia prima che il file venga consegnato: l'utente riceve un documento strutturalmente pulito, privo di sezioni nascoste, link dannosi e oggetti non conformi alle politiche aziendali. Adaptive Sandbox l'intento della minaccia prima o durante la consegna: ogni livello del documento viene eseguito, ogni comportamento viene osservato e ogni indicatore di compromissione viene estratto e registrato.
Per le organizzazioni che operano in ambienti ad alto rischio, questa combinazione risulta particolarmente efficace. La tecnologia Deep CDR™ garantisce che i documenti che raggiungono gli utenti non possano eseguire logiche nascoste. Adaptive Sandbox che venga compreso l'intento comportamentale di ogni documento, compreso ogni livello di un file concatenato. Nessuna delle due tecnologie richiede una conoscenza preliminare della tecnica di attacco specifica per essere efficace. Entrambe operano sulla struttura del file e sul comportamento del suo contenuto, non su firme note o feed di intelligence sulle minacce.
Pensieri conclusivi
La tecnica di attacco tramite file PDF concatenati illustra una categoria di minacce che i sistemi di sicurezza basati sul rilevamento non sono stati progettati per affrontare. Non c'è alcuna firma malware da individuare. Non c'è alcun exploit da rilevare. C'è solo una riorganizzazione strutturale di un formato di file legittimo che induce sistemi diversi a interpretare le cose in modo diverso.
Per i responsabili e i direttori IT, le implicazioni operative sono chiare: gli strumenti di scansione attualmente in uso potrebbero analizzare una versione del documento diversa da quella aperta dagli utenti.
Per i responsabili della conformità e della gestione dei rischi, ciò comporta una lacuna nella governance: la traccia di audit relativa alla sicurezza dei file potrebbe non rispecchiare il contenuto effettivamente trasmesso.
Per i dirigenti di alto livello, l'esposizione finanziaria è notevole: il costo medio di una violazione causata da un attacco di phishing riuscito supera ormai i 4,88 milioni di dollari, e gli attacchi che eludono i controlli standard sono tra i più costosi da risolvere.
Per i consulenti legali e aziendali e i responsabili della protezione dei dati, i sistemi di intelligenza artificiale che agiscono sui contenuti nascosti dei documenti senza alcuna revisione umana o visibilità in termini di sicurezza rappresentano un rischio emergente e concreto.
La tecnologia OPSWAT CDR™ e Adaptive Sandbox questa lacuna da entrambe le direzioni. La tecnologia Deep CDR™ elimina le condizioni strutturali che consentono l’esistenza di tali minacce verificando la struttura dei file, rimuovendo tutte le sezioni nascoste e in conflitto dei documenti e rigenerando un output pulito e verificato; in questo modo garantisce che ogni file che entra nell’ambiente contenga esattamente lo stesso contenuto che è stato ispezionato. Adaptive Sandbox che nulla sfugga all'esame: eseguendo un'analisi sensibile alla struttura su ogni livello di documento incorporato, eseguendo ciascuno in modo indipendente e correlando i risultati al file originale, mette in luce l'intento comportamentale delle minacce che nessun trucco di analisi sintattica può nascondere. Insieme, queste tecnologie garantiscono che ciò che gli utenti ricevono sia sicuro e che l'obiettivo per cui gli aggressori hanno progettato il file sia pienamente compreso.
Risorse aggiuntive
- Visualizza il portafoglioOPSWAT
- Scarica la scheda tecnica: Tecnologia Deep CDR™ e Adaptive Sandbox

